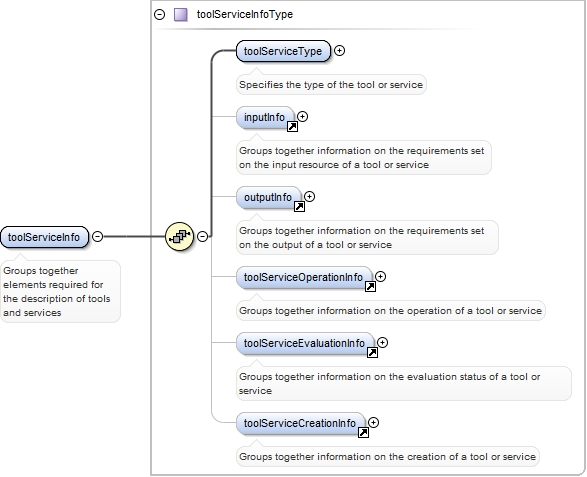
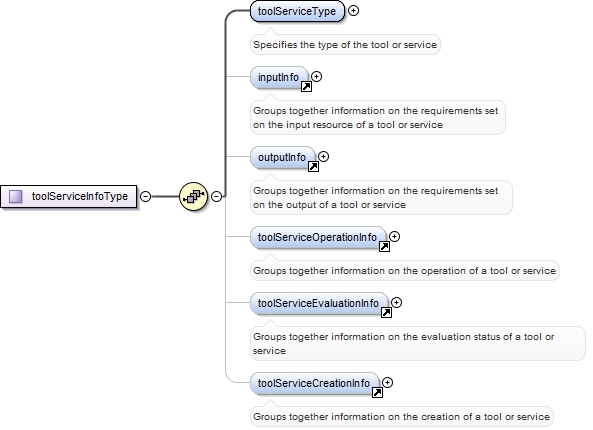
<xs:complexType name="toolServiceInfoType">
<xs:annotation>
<xs:appinfo>
<render-short>toolService ({toolServiceType})</render-short>
</xs:appinfo>
</xs:annotation>
<xs:sequence>
<xs:element name="toolServiceType">
<xs:annotation>
<xs:documentation>Specifies the type of the tool or service</xs:documentation>
<xs:appinfo>
<label>Software-specific type</label>
</xs:appinfo>
</xs:annotation>
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:maxLength value="100"/>
<xs:enumeration value="tool">
<xs:annotation>
<xs:documentation>A device that performs one or more of the tasks listed in the ForeseenUseInfo component</xs:documentation>
<xs:appinfo>
<label>Tool</label>
</xs:appinfo>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="webService">
<xs:annotation>
<xs:documentation>A form in which NLP taks are realized and delivered to a user, without the need of acquiring and installing the corresponding tools</xs:documentation>
<xs:appinfo>
<label>Web service</label>
</xs:appinfo>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="workflow">
<xs:annotation>
<xs:documentation>A more of less fixed integrated organisation of tools applied for solving a combinaton of tasks</xs:documentation>
<xs:appinfo>
<label>Workflow</label>
</xs:appinfo>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="other"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
<!--
<xs:element name="function" type="functionType" maxOccurs="unbounded">
<xs:annotation>
<xs:documentation>Specifies the function/operation/task that an NLP/MT tool performs</xs:documentation>
<xs:appinfo>
<relation>one-to-many</relation>
<label>Task of NLP/MT tool</label>
</xs:appinfo>
</xs:annotation>
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:maxLength value="100"/>
<xs:enumeration value="alignment">
<xs:annotation>
<xs:appinfo>
<label>Alignment</label>
</xs:appinfo>
<xs:documentation>Establishment of translational equivalences between structural units (words, sentences etc.) of a text in a given language and a text with similar meaning in other language(s)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="phraseAlignment">
<xs:annotation>
<xs:appinfo>
<label>Phrase Alignment</label>
</xs:appinfo>
<xs:documentation>Alignment at phrase level</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="sentenceAlignment">
<xs:annotation>
<xs:appinfo>
<label>Sentence Alignment</label>
</xs:appinfo>
<xs:documentation>Alignment at sentence level</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="wordAlignment">
<xs:annotation>
<xs:appinfo>
<label>Word Alignment</label>
</xs:appinfo>
<xs:documentation>Alignment at word level</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="webCrawling">
<xs:annotation>
<xs:appinfo>
<label>Web crawling</label>
</xs:appinfo>
<xs:documentation>The use of bots that crawl the web (crawlers) in order to spot pages that match user-set criteria and download them to create large Fosets</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="languageIdentification">
<xs:annotation>
<xs:appinfo>
<label>Language identification</label>
</xs:appinfo>
<xs:documentation>The task/process of guessing what natural language a text or text segment is written in.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="termExtraction">
<xs:annotation>
<xs:appinfo>
<label>Term extraction</label>
</xs:appinfo>
<xs:documentation>The act/process of identifying and extracting candidate terms from a domain-specific corpus</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="lexiconAcquisitionFromCorpora">
<xs:annotation>
<xs:appinfo>
<label>Lexicon acquisition from corpora</label>
</xs:appinfo>
<xs:documentation>The task/process of constructing lexical resources from corpora</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="lexiconExtractionFromLexica">
<xs:annotation>
<xs:appinfo>
<label>Lexicon extraction from lexica</label>
</xs:appinfo>
<xs:documentation>The task/process of constructing lexical resources based on the restructuring of lexical information contained in lexica (e.g. by parsing definitions or using syntactic information attached to lemmas)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="bilingualLexiconInduction">
<xs:annotation>
<xs:appinfo>
<label>Bilingual lexicon induction</label>
</xs:appinfo>
<xs:documentation>The task/process of inducing word translations from monolingual or comparable corpora in two languages</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="spellChecking">
<xs:annotation>
<xs:appinfo>
<label>Spell Checking</label>
</xs:appinfo>
<xs:documentation>The task/process of checking the accuracy of spelling of a word in a text and correcting it according to the accepted form</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="languageModelling">
<xs:annotation>
<xs:appinfo>
<label>Language modelling</label>
</xs:appinfo>
<xs:documentation>The construction of statistical or Machine Learning language models</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="trainingOfLanguageModels">
<xs:annotation>
<xs:appinfo>
<label>Training of language models</label>
</xs:appinfo>
<xs:documentation>The task/process of training (statistical) language models that that can estimate the distribution of natural language as accurately as possible.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="annotation">
<xs:annotation>
<xs:appinfo>
<label>Annotation</label>
</xs:appinfo>
<xs:documentation>The process/task of adding annotations (annotation types) to an item.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="annotationOfDocumentStructure">
<xs:annotation>
<xs:appinfo>
<label>Annotation of document structure</label>
</xs:appinfo>
<xs:documentation>The task/process of annotating the internal structure of a document (e.g. book chapters, sections in a journal article, title, preface etc.)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="structuralAnnotation">
<xs:annotation>
<xs:appinfo>
<label>Structural annotation</label>
</xs:appinfo>
<xs:documentation>The task/process of segmenting a text and recognizing textual structural units (paragraphs, sentences, words etc.)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="sentenceSplitting">
<xs:annotation>
<xs:appinfo>
<label>Sentence splitting</label>
</xs:appinfo>
<xs:documentation>The task/process of recognizing and tagging sentence boundaries in a text</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="paragraphSplitting">
<xs:annotation>
<xs:appinfo>
<label>Paragraph splitting</label>
</xs:appinfo>
<xs:documentation>The task/process of segmenting a text into paragraphs and marking their boundaries</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="tokenization">
<xs:annotation>
<xs:appinfo>
<label>Tokenization</label>
</xs:appinfo>
<xs:documentation>The task/process of recognizing and tagging tokens (words, punctuation marks, digits etc.) in a text</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="lemmatization">
<xs:annotation>
<xs:appinfo>
<label>Lemmatization</label>
</xs:appinfo>
<xs:documentation>Lemmatisation (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word's lemma, or dictionary form. [Wikipedia]</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="stemming">
<xs:annotation>
<xs:appinfo>
<label>Stemming</label>
</xs:appinfo>
<xs:documentation>The task/process of cutting off the ends of words (mainly inflectional affixes but sometimes also derivational affixes) aiming to relate words to a base form.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="poSTagging">
<xs:annotation>
<xs:appinfo>
<label>PoS Tagging</label>
</xs:appinfo>
<xs:documentation>The task/process of marking words with the part of speech (word category, e.g. noun, verb etc.) to which they belong</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="belowPoSTagging">
<xs:annotation>
<xs:appinfo>
<label>Below PoS Tagging</label>
</xs:appinfo>
<xs:documentation>The annotation of words with morphological information besides the part of speech and dependent upon it (e.g. for nouns: gender, number and case; for verbs: tense, label number, person etc.)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="wordSegmentation">
<xs:annotation>
<xs:appinfo>
<label>Word segmentation</label>
</xs:appinfo>
<xs:documentation>The task/process of segmenting (cutting) a word into root and affixes</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="annotationOfCompounds">
<xs:annotation>
<xs:appinfo>
<label>Annotation of compounds</label>
</xs:appinfo>
<xs:documentation>The task/process of marking compounds (multi-word units considered as a whole) and their parts</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="annotationOfDerivationalFeatures">
<xs:annotation>
<xs:appinfo>
<label>Annotation of derivational features</label>
</xs:appinfo>
<xs:documentation>The task/process of adding annotations relevant to the derivational level of analysis (e.g. recognizing derivational affixes, tagging their meaning etc.)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="chunking">
<xs:annotation>
<xs:appinfo>
<label>Chunking</label>
</xs:appinfo>
<xs:documentation>The task/process of dividing a sentence into chunks (non-overlapping text segments consisting of a head and preceding function words and/or modifiers)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="parsing">
<xs:annotation>
<xs:appinfo>
<label>Parsing</label>
</xs:appinfo>
<xs:documentation>The task/process of recognizing and marking the syntactic structure of a text or text segment</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="constituencyParsing">
<xs:annotation>
<xs:appinfo>
<label>Constituency parsing</label>
</xs:appinfo>
<xs:documentation>The task/process of identifying and marking constituents (phrases, governed by a head and including function words and/or modifiers ) in a text or text segment</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="dependencyConversion">
<xs:annotation>
<xs:appinfo>
<label>Dependency conversion</label>
</xs:appinfo>
<xs:documentation>The task/process of converting constituency structures to dependency trees</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="dependencyParsing">
<xs:annotation>
<xs:appinfo>
<label>Dependency parsing</label>
</xs:appinfo>
<xs:documentation>The task/process of identifying and marking the grammatical structure of a sentence, establishing relationships between "head" words and words which modify those heads</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="namedEntityRecognition">
<xs:annotation>
<xs:appinfo>
<label>Named Entity Recognition</label>
</xs:appinfo>
<xs:documentation>A subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="semanticAnnotation">
<xs:annotation>
<xs:appinfo>
<label>Semantic Annotation</label>
</xs:appinfo>
<xs:documentation>The task/process of marking text units with semantic types (e.g. semantic classes, emotions etc.)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="semanticClassLabelling">
<xs:annotation>
<xs:appinfo>
<label>Semantic Class Labelling</label>
</xs:appinfo>
<xs:documentation>The task/process of classifying words in a text according to a set of semantic classes (types).</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="semanticRelationLabelling">
<xs:annotation>
<xs:appinfo>
<label>Semantic Relation Labelling</label>
</xs:appinfo>
<xs:documentation>The task/process of attaching tags indicating the semantic relation that holds between units of a text.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="semanticRoleLabelling">
<xs:annotation>
<xs:appinfo>
<label>Semantic Role Labelling</label>
</xs:appinfo>
<xs:documentation>The task/process of attaching labels that correspond to the roles that the arguments of a predicate take in an event</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="frameSemanticParsing">
<xs:annotation>
<xs:appinfo>
<label>Frame-semantic parsing</label>
</xs:appinfo>
<xs:documentation>The task/process of recognising and labelling in a text predicate argument structures and the semantic roles of the constituents, in accordance to the frame semantics theory.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="coReferenceAnnotation">
<xs:annotation>
<xs:appinfo>
<label>Co-reference annotation</label>
</xs:appinfo>
<xs:documentation>The task/process of attaching tags to a text unit and linking it to other text units that refer to the same entity.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="formatConversion">
<xs:annotation>
<xs:appinfo>
<label>Format conversion</label>
</xs:appinfo>
<xs:documentation>The task/process of converting (changing) the format of a resource into another (e.g. PDF to TXT or XML)</xs:documentation>
</xs:annotation>
</xs:enumeration>
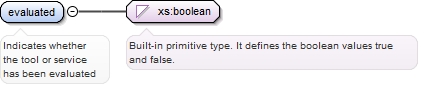
<xs:enumeration value="evaluation">
<xs:annotation>
<xs:appinfo>
<label>Evaluation</label>
</xs:appinfo>
<xs:documentation>The task/process of assessing the quality of a resource, e.g. based on the contents (for a dataset) or performance (for a tool or service)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="textCategorization">
<xs:annotation>
<xs:appinfo>
<label>Text categorization</label>
</xs:appinfo>
<xs:documentation>The process/task of assigning documents into classes or categories.</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="topicDetection">
<xs:annotation>
<xs:appinfo>
<label>Topic detection</label>
</xs:appinfo>
<xs:documentation>The task/process of identifying the topic of a text or dataset (e.g. by clustering keywords or using topic models)</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="validation">
<xs:annotation>
<xs:appinfo>
<label>Validation</label>
</xs:appinfo>
<xs:documentation>The task/process of confirming that a system/data resource meets the specifications and fulfills its intended purpose</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="corpusViewing">
<xs:annotation>
<xs:appinfo>
<label>Corpus viewing</label>
</xs:appinfo>
<xs:documentation>The task/process of viewing the contents of a corpus as performed by human beings</xs:documentation>
</xs:annotation>
</xs:enumeration>
<xs:enumeration value="other"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
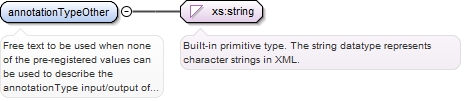
<xs:element name="functionOther" type="xs:string" minOccurs="0">
<xs:annotation>
<xs:documentation>Free text to be used when none of the pre-registered values for function can be used to describe the function of a tool</xs:documentation>
<xs:appinfo>
<label>Function (other)</label>
<condition>Display only if function=other</condition>
</xs:appinfo>
</xs:annotation>
</xs:element>
-->
<!--
<xs:element name="languageDependent" type="xs:boolean">
<xs:annotation>
<xs:documentation>Indicates whether the operation of the tool or service is language dependent or not</xs:documentation>
<xs:appinfo>
<label>Language dependent</label>
</xs:appinfo>
</xs:annotation>
</xs:element>
-->
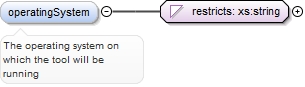
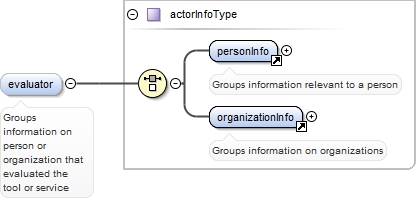
<xs:element ref="inputInfo" minOccurs="0">
<xs:annotation>
<xs:documentation>Groups together information on the requirements set on the input resource of a tool or service</xs:documentation>
<xs:appinfo>
<recommended>true</recommended>
<label>Input</label>
</xs:appinfo>
</xs:annotation>
</xs:element>
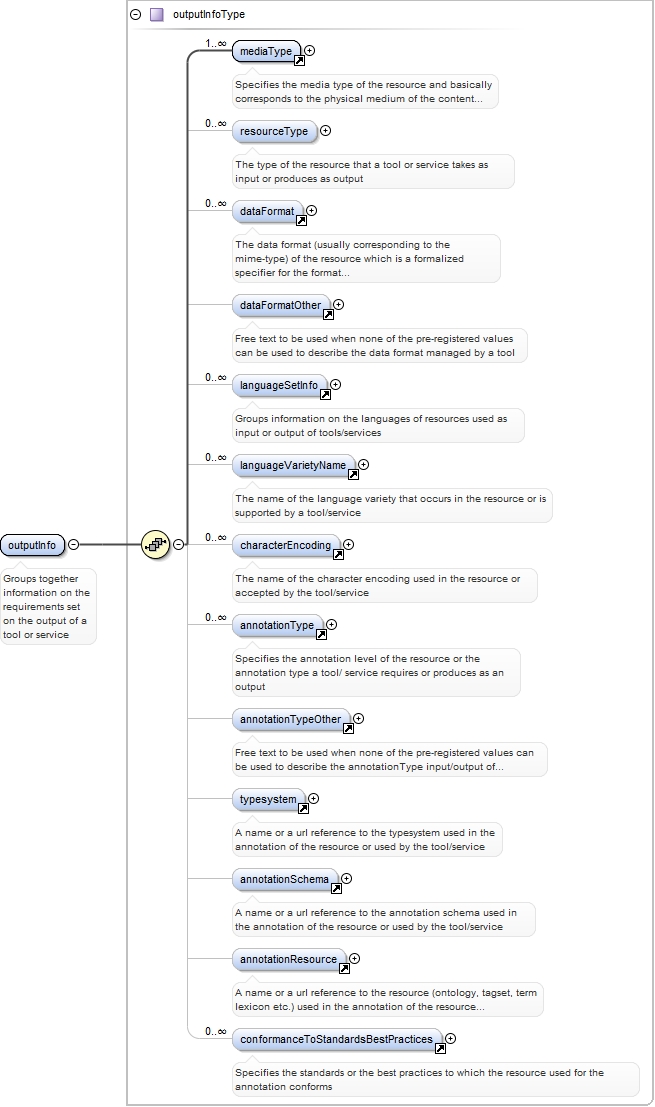
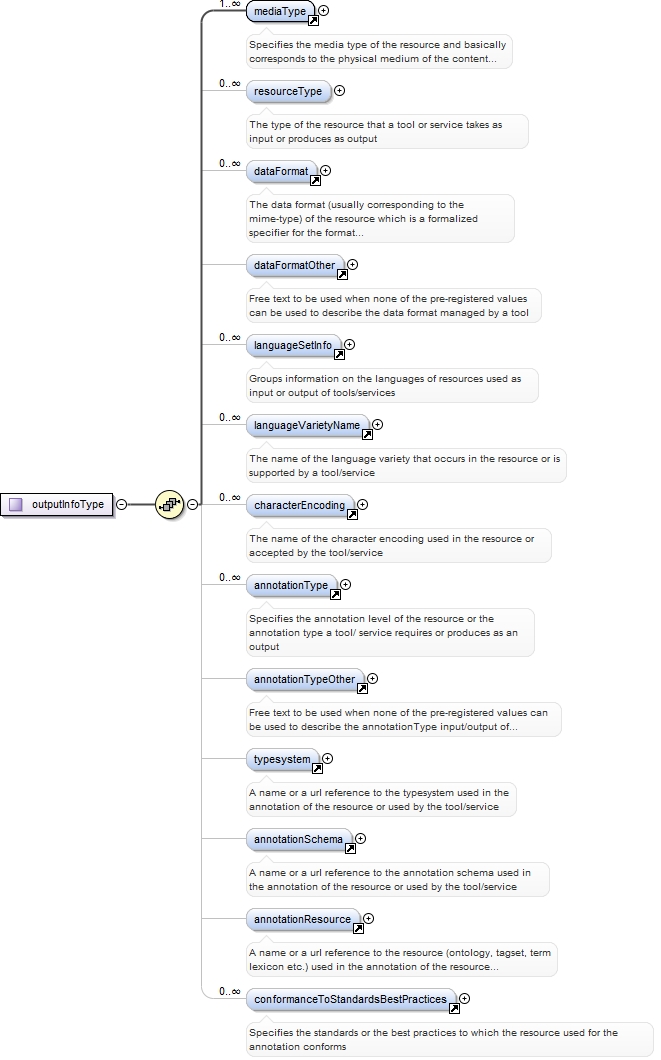
<xs:element ref="outputInfo" minOccurs="0">
<xs:annotation>
<xs:documentation>Groups together information on the requirements set on the output of a tool or service</xs:documentation>
<xs:appinfo>
<recommended>true</recommended>
<label>Output</label>
</xs:appinfo>
</xs:annotation>
</xs:element>
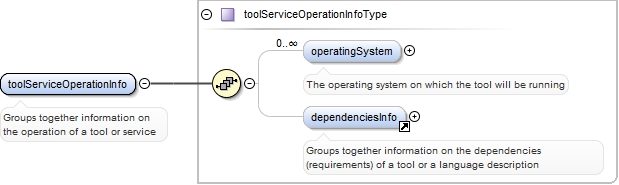
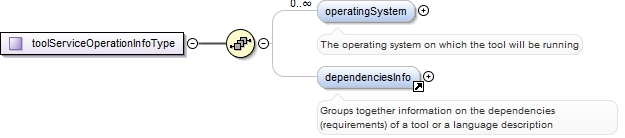
<xs:element ref="toolServiceOperationInfo" minOccurs="0">
<xs:annotation>
<xs:documentation>Groups together information on the operation of a tool or service</xs:documentation>
<xs:appinfo>
<recommended>true</recommended>
<label>Tool / Service operation</label>
</xs:appinfo>
</xs:annotation>
</xs:element>
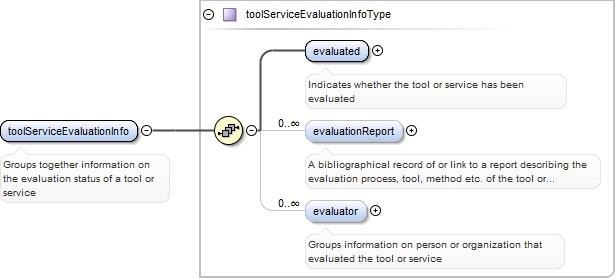
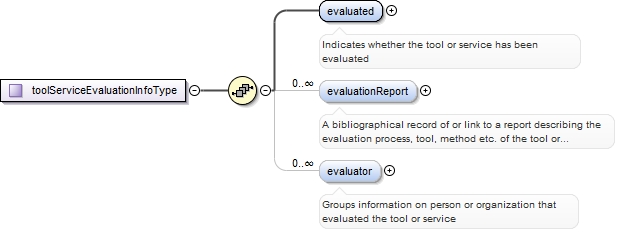
<xs:element ref="toolServiceEvaluationInfo" minOccurs="0">
<xs:annotation>
<xs:documentation>Groups together information on the evaluation status of a tool or service</xs:documentation>
<xs:appinfo>
<recommended>true</recommended>
<label>Tool / Service evaluation</label>
</xs:appinfo>
</xs:annotation>
</xs:element>
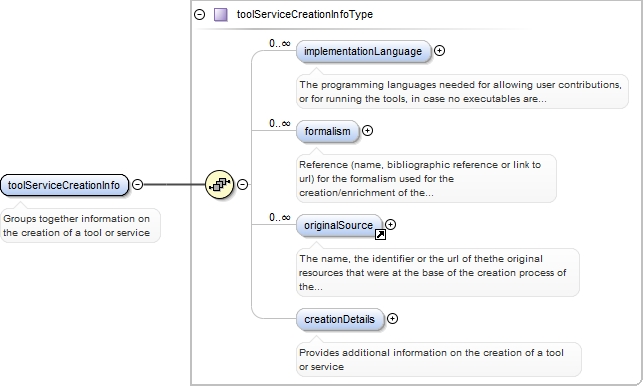
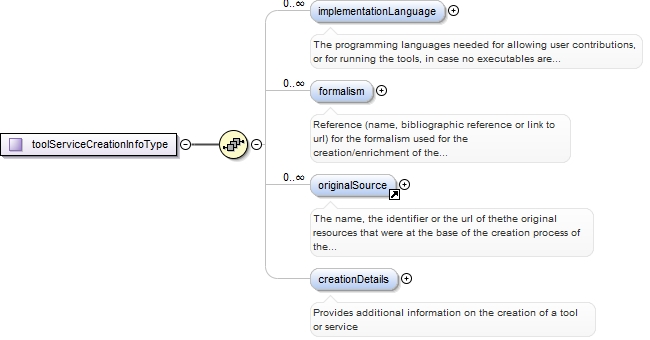
<xs:element ref="toolServiceCreationInfo" minOccurs="0">
<xs:annotation>
<xs:documentation>Groups together information on the creation of a tool or service</xs:documentation>
<xs:appinfo>
<label>Tool / Service creation</label>
</xs:appinfo>
</xs:annotation>
</xs:element>
</xs:sequence>
</xs:complexType> |