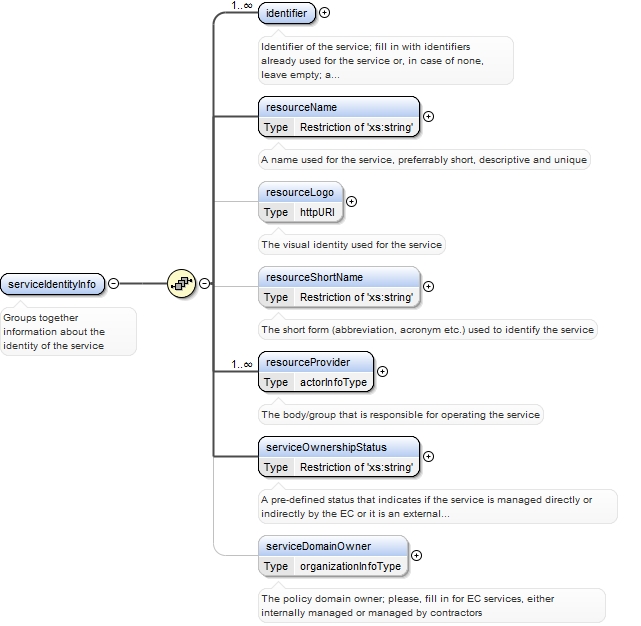
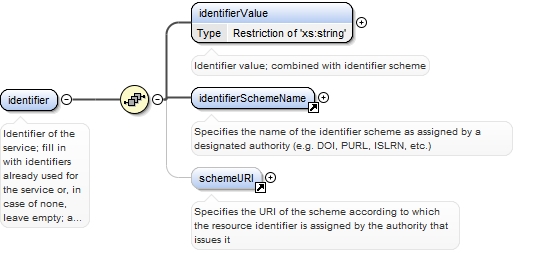
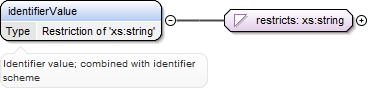
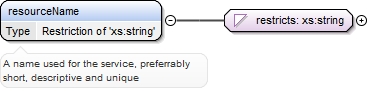
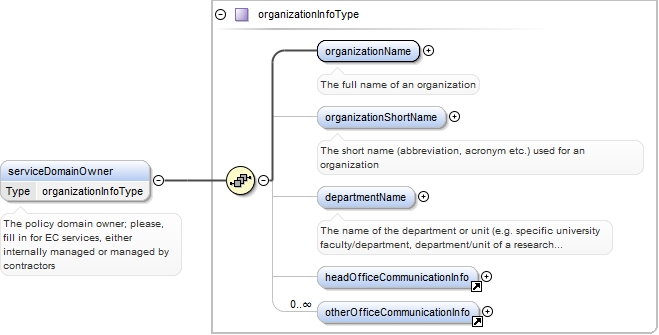
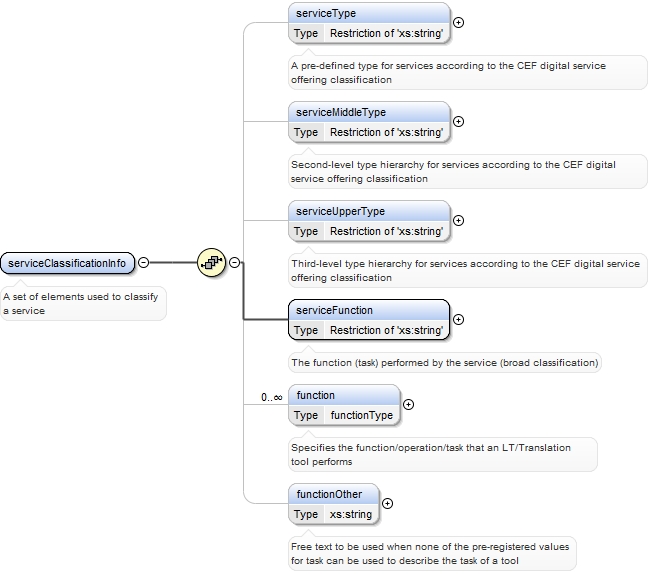
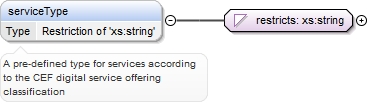
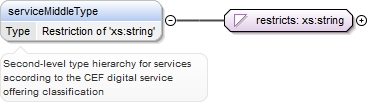
| enumeration |
http://w3id.org/meta-share/omtd-share/LexiconAcquisitionFromCorpora |
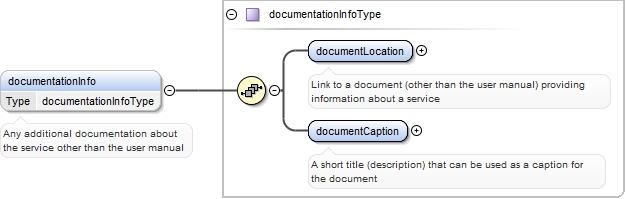
The task/process of constructing lexical resources from corpora |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TextAndDataMining |
The automated processing of unstructured text and/or structured data leading to the extraction of previously hidden knowledge. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TextCategorization |
The task/process of assigning documents into classes or categories |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/QuestionAnswering |
The task/process where computer systems try to automatically answer questions posed by users in the form of natural language. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SentimentAnalysis |
The process/task of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer's attitude towards a particular topic, product, etc. is positive, negative, or neutral |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/KnowledgeRepresentation |
The task/process of representing information about entities in a form that machines are capable of understanding it |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/EmotionDetection |
The process/task of identifying types of feelings (e.g. anger, fear, happiness, sadness, etc.) in the linguistic expression of texts or facial expressions |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TermExtraction |
The act/process of identifying and extracting candidate terms from a domain-specific corpus |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/EventDetection |
The process/task of identifying events in data (text, video, images etc.), usually combined with their classification into types of events and recognition of the event attributes (e.g. time, place, participants and duration) |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/NamedEntityRecognition |
A subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/InformationRetrieval |
The activity of obtaining information resources relevant to an information need from a collection of information resources; searches can be based on full-text or other content-based indexing |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SemanticSearch |
A type of search that seeks to improve search accuracy by understanding the searcher's intent and the contextual meaning of terms as they appear in the searchable dataspace, whether on the Web or within a closed system, to generate more relevant results. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Alignment |
Establishment of translational equivalences between structural units (words, sentences etc.) of a text in a given language and a text with similar meaning in other language(s) |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Summarization |
The process/task of reducing one or more textual documents with a computer program in order to create a summary that retains the most important points of the original document(s). |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Crawling |
The use of bots that crawl the web (crawlers) in order to spot content that matches user-set criteria and download them to create large datasets |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/LanguageModelling |
The construction of statistical or Machine Learning language models |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Anonymization |
The task/process by which data become anonymous, i.e. "in such a way that the data subject is not or no longer identifiable." (from GDPR) |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/FormatConversion |
The task/process of converting (changing) the format of a resource into another (e.g. PDF to TXT or XML) |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/LanguageIdentification |
The task/process of guessing what natural language a text or text segment is written in. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Validation |
The task/process of confirming that a system/data resource meets the specifications and fulfills its intended purpose |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Paraphrasing |
A task/process whereby a text fragment is reproduced with another text fragment that conveys the same or similar information |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Parsing |
The task/process of recognizing and marking the syntactic structure of a text or text segment |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WordSenseDisambiguation |
The process/task of identifying which sense of a word with multiple meanings is used in a particular context; the selection of the sense is made from a list of the word's senses. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TextAndDataAnalytics |
The process/task of converting unstructured text and data into high-quality structured data that can be further analysed to extract knowledge, support decision making etc. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MachineTranslation |
The automatic translation of a text from one language into another performed by software without human involvement |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SentenceSplitting |
The task/process of recognizing and tagging sentence boundaries in a text |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tokenization |
The task/process of recognizing and tagging tokens (words, punctuation marks, digits etc.) in a text |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/ParagraphSplitting |
The task/process of segmenting a text into paragraphs and marking their boundaries |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Lemmatization |
Lemmatisation (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word's lemma, or dictionary form |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SemanticAnnotation |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MorphologicalAnnotation |
The task/process of adding annotations pertaining to the morphological level of analysis (e.g. gender, number, person etc.) |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/DiscourseAnnotationTypeAnnotation |
The task/process of adding annotations relevant to discourse, such as discourse structure, discourse markers etc. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SpeechAnnotation |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SpeechRecognition |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TextToSpeechSynthesis |
The task/process of converting natural language text into speech |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/AutomaticSubtitling |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/CrossLingualSearch |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/DiscourseAnnotation |
The task/process of adding annotations relevant to discourse, such as discourse structure, discourse markers etc. |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MultimediaAnnotation |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Transliteration |
|
| enumeration |
http://w3id.org/meta-share/omtd-share/ComputerAidedTranslation |
A form of translation performed by a human translation with the aid of software programmes |
|